rtmp+flv服务搭建与基于python的flv流获取
背景
最近有个项目,用户可以在微信小程序上直接预览监控点,而不用额外下载 APP
之前只能通过 APP 预览,基联 APP 的接口编写过模拟多路并行预览的工具
但是小程序的鉴权方式完全不一致,而且预览流程也完全不一样(基于 HTTP+FLV),针对小程序的预览模拟,需要编写另外的脚本工具
另外也立项了 RTMP 推流的需求,为了提前了解下相关协议,也为了方便脚本调试,尝试在本地搭建了相关服务并进行了脚本模拟拉流测试
本地服务搭建
本地搭建的推流、拉流框架如下:
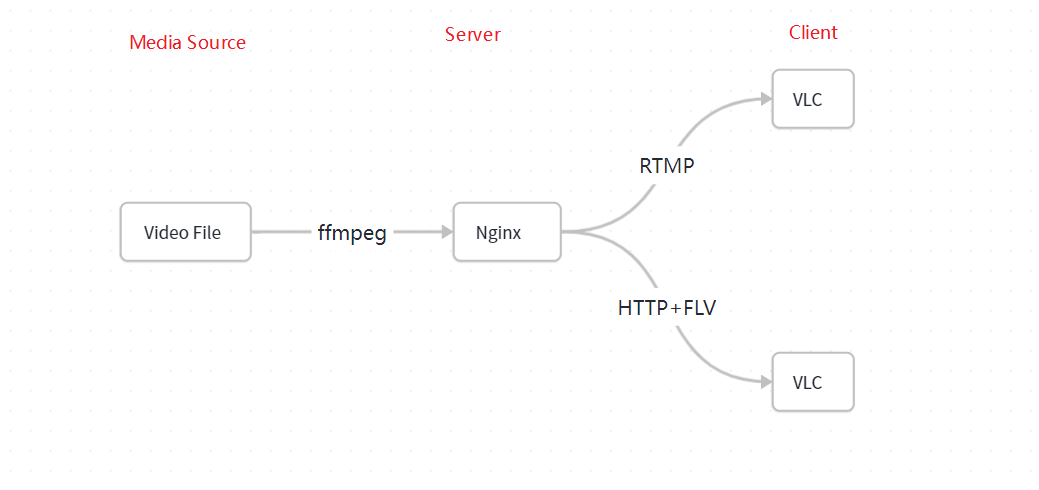
- 启动 nginx,开启 RTMP 服务,配置 HTTP 开启 FLV 服务
- 通过 ffmpeg 将视频文件转码推流到 RTMP 服务
- 通过 VLC 等拉流工具,使用 RTMP 协议或 FLV 协议进行拉流
nginx-http-flv-module 源码编译
nginx 本身是不支持流媒体功能的,开发者们为其添加了额外的流媒体功能,比如开源的 nginx-http-flv-module 但需要重新编译
Windows 上源码编译 nginx 环境配置很麻烦,直接找编译好的包,解压就能使用
万恶的 CSDN 上倒是有很多,但都要付费下载
经过不懈努力终于在 github 上找到了一个编译好的包:https://github.com/chen-jia-hao/nginx-win-httpflv-1.19.0
nginx 配置文件修改
修改 conf/nginx.conf
worker_processes 1;
#error_log logs/error.log;
#error_log logs/error.log notice;
#error_log logs/error.log info;
#error_log logs/error.log debug;
#pid logs/nginx.pid;
events {
worker_connections 1024;
}
rtmp_auto_push on;
rtmp_auto_push_reconnect 1s;
rtmp_socket_dir temp;
# 添加RTMP服务
rtmp {
server {
listen 1935; # 监听端口
chunk_size 4000;
application live {
live on;
gop_cache on; # GOP缓存,on时延迟高,但第一帧画面加载快。off时正好相反,延迟低,第一帧加载略慢。
}
}
}
# HTTP服务
http {
include mime.types;
default_type application/octet-stream;
#access_log logs/access.log main;
server {
listen 80; # 监听端口
location / {
add_header Access-Control-Allow-Origin *;
add_header Access-Control-Allow-Methods 'GET, POST, OPTIONS';
add_header Access-Control-Allow-Headers 'DNT,X-Mx-ReqToken,Keep-Alive,User-Agent,X-Requested-With,If-Modified-Since,Cache-Control,Content-Type,Authorization';
if ($request_method = 'OPTIONS') {
return 204;
}
root html;
}
location /live {
flv_live on; #打开HTTP播放FLV直播流功能
chunked_transfer_encoding on; #支持'Transfer-Encoding: chunked'方式回复
add_header 'Access-Control-Allow-Origin' '*'; #添加额外的HTTP头
add_header 'Access-Control-Allow-Credentials' 'true'; #添加额外的HTTP头
}
location /stat.xsl {
root html;
}
location /stat {
rtmp_stat all;
rtmp_stat_stylesheet stat.xsl;
}
location /control {
rtmp_control all; #rtmp控制模块的配置
}
}
}
启动 nginx
start nginx -c conf/nginx.conf
ffmpeg 推流
ffmpeg -stream_loop -1 -re -i 诸葛亮王朗.mp4 -vcodec libx264 -acodec aac -f flv rtmp://localhost:1935/live/123
VLC 拉流
VLC 媒体-打开网络串流:
http://localhost/live?port=1935&app=live&stream=123
随后即可播放:

Python 获取 FLV 视频流
因为目的是模拟多路并发预览,考虑用 Python 脚本实现多路并行获取 FLV 视频流,调研对比了多种实现方案
基于 OpenCV 库
OpenCV 库提供了简单的 API,可直接获取网络视频流保存到本地文件:
import cv2
def save_video(flv_url):
cap = cv2.VideoCapture(flv_url)
fps = cap.get(cv2.CAP_PROP_FPS)
size = (int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)), int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)))
fourcc = cv2.VideoWriter_fourcc('F', 'L', 'V', '1')
video_file = 'video/test.flv'
out_video = cv2.VideoWriter(video_file, fourcc, fps, size)
rval, frame = cap.read()
while rval:
out_video.write(frame)
rval, frame = cap.read()
cv2.waitKey(1)
cap.release()
out_video.release()
实测保存的本地文件可以用 VLC 或 ffplay 直接播放
但我的需求是模拟多路并发预览,OpenCV 库提供的获取流方法是阻塞式的,没法套用已有的 async 协程框架,想要实现多并发得用多线程等方式实现
为了复用之前的框架,同时也为了更深入地理解 FLV 协议,还是决定用 asyncio 直接建立 Socket 连接试试
基于 Socket 连接
HTTP-FLV,即将音视频数据封装成 FLV,然后通过 HTTP 协议传输给客户端。
建立连接后,需要发送 FLV 协议规定的 HTTP 请求头,比如用 VLC 拉流,抓包看到建立 TCP 连接后,发送的 HTTP 请求及响应如下:

因为服务器并不知道流的长度,所以响应的 HTTP 头并没有携带 Content-Length 字段,而是携带 Transfer-Encoding: chunked 字段,这样客户端就会一直接收数据了
编写脚本用 asyncio 直接建立 Socket 连接,获取数据保存到本地文件:
import asyncio
import async_timeout
from urllib.parse import urlparse
async def save_video(flv_url):
video_file = "video/test.flv"
if os.path.exists(video_file):
os.remove(video_file)
flv_hostname = urlparse(flv_url).hostname
flv_port = "80"
flv_path = urlparse(flv_url).path
flv_query = urlparse(flv_url).query
try:
with async_timeout.timeout(20):
reader, writer = await asyncio.open_connection(flv_hostname, flv_port)
print("Flv Server Connected")
except asyncio.TimeoutError:
print("Connection Timeout!")
except ConnectionError:
print("Connection Failed!")
try:
header = """GET {}?{} HTTP/1.1
Host: {}
Accept: */*
Accept-Language: zh_CN
User-Agent: VLC/3.0.8 LibVLC/3.0.8
Range: bytes=0-
""".format(flv_path, flv_query, flv_hostname)
writer.write(header.encode())
await writer.drain()
recv_data = await reader.read(1024)
recv_header = recv_data.split(b'\r\n\r\n')[0]
print(recv_header.decode())
if 'HTTP/1.1 200 OK' in recv_header.decode():
print("Video Get Success")
if recv_data.split(b'\r\n\r\n')[1]:
flv_header_index = recv_data.split(b'\r\n\r\n')[1].find(b'\x46\x4C\x56')
flv_header = recv_data.split(b'\r\n\r\n')[1][flv_header_index:]
with open(video_file, 'wb') as fd:
fd.write(flv_header)
else:
recv_data = await reader.read(1024)
flv_header_index = recv_data.find(b'\x46\x4C\x56')
flv_header = recv_data[flv_header_index:]
with open(video_file, 'wb') as fd:
fd.write(flv_header)
while True:
recv_data = await reader.read(1024)
with open(video_file, 'wb') as fd:
fd.write(recv_data)
except ConnectionError:
print("Connection Failed!")
其中 b'\x46\x4C\x56' 对应 FLV,即 FLV 头部,从服务器响应的 FLV 头部开始的数据保存到文件中,但是保存下来的文件却无法通过 ffplay 或 VLC 播放
对比保存的文件内容,与抓包结果一致:

再对比通过 OpenCV 保存的文件,虽然可以播放,但是与抓包结果的 FLV 头部却不一样:

说明 OpenCV 在获取视频流数据、保存到文件的时候就对头部做了一些处理,让其可以正常播放
而直接把通过 Socket 获取到的二进制数据保存到文件,其 FLV 头部并不是合法的格式,所以无法直接播放
基于 requests
查找资料的时候发现,基于 requests 库可以直接用 get 方法获取 HTTP-FLV 数据,同样可以保存到文件:
import requests
def save_video_requests(flv_url):
video_file = "video/test_requests.flv"
if os.path.exists(video_file):
os.remove(video_file)
chunk_size = 1024
response = requests.get(flv_url, stream=True, verify=False)
with open(video_file, 'wb') as file:
for data in response.iter_content(chunk_size = chunk_size):
file.write(data)
file.flush()
尝试了一下发现此方法保存的文件同样可以直接播放,对比抓包结果与文件内容如下:

发现好像保存的文件就是去掉了抓包结果中的一些换行符(0d0a),部分换行符前面还有一些数据,看来也是保存的时候底层做了一些处理。
其实换行符和部分换行符前面的数据是 HTTP 分块传输编码规则导致的:
- 每个分块包含两个部分,长度头和数据块;
- 长度头是以 CRLF(回车换行,即
\r\n)结尾的一行明文,用 16 进制数字表示长度; - 数据块紧跟在长度头后,最后也用 CRLF 结尾,但数据不包含 CRLF;
- 最后用一个长度为 0 的块表示结束,即
0\r\n\r\n。
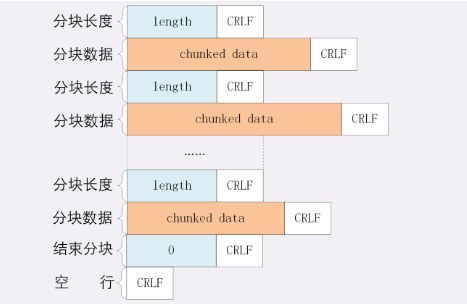
所以我们只要在保存数据的时候,只保存 chunked data,把 length 和换行符都过滤掉就可以了
这原理看起来简单,但真要直接处理二进制数据还比较复杂
不过既然 requests 可以实现,那协程的 aiohttp 应该也可以吧
基于 aiohttp
import aiohttp
async def save_video_aiohttp(flv_url):
video_file = "video/test_aiohttp.flv"
if os.path.exists(video_file):
os.remove(video_file)
chunk_size = 1024
conn = aiohttp.TCPConnector()
async with aiohttp.ClientSession(connector=conn) as session:
async with session.get(flv_url) as response:
with open(video_file, 'wb') as file:
while True:
data = await response.content.read(chunk_size)
if not data:
break
file.write(data)
file.flush()
测试能通过 ffplay 和 VLC 正常播放,aiohttp 套入协程框架也很方便,最终就决定用这种方式了
参考
- https://www.cnblogs.com/hhmm99/p/16050844.html
- https://github.com/winshining/nginx-http-flv-module
- https://github.com/chen-jia-hao/nginx-win-httpflv-1.19.0
- https://www.cnblogs.com/vczf/p/14813438.html
- https://blog.csdn.net/Enderman_xiaohei/article/details/102626855