线程池参数设置不合理导致的消息丢失问题
问题背景
- 充电桩使用4G流量卡上网,在4G信号不稳定的情况下,可能出现设备离线
- 生产环境中,偶现充电桩掉线后,始终没有在云平台重新上线,导致用户扫码提示设备故障无法使用
- 而实际设备已经在线,在云平台 WEB 上手动同步设备信息后,设备恢复在线状态,可以正常使用
业务流程
以设备上线为例,设备首先和云平台的设备连接层建立socket连接交互,连接层模块会产生一个上线事件,发到kafka的topic上,下游模块消费后,经过业务处理,转发给云平台的设备管理模块,设备管理模块收到消息后修改对应的设备在线状态、触发消息提醒。
participant 设备 as d
participant 设备连接层 as c
participant kafka as k
participant 下游模块 as h
participant 云平台 as b
d->c: 建立连接
note over d, c: 长连接
c->k: 设备上线事件
k->h: 消费消息
note over h: 业务处理
h->b: 消息转发
note over b: 产生消息提示
note over b: 修改设备在线状态
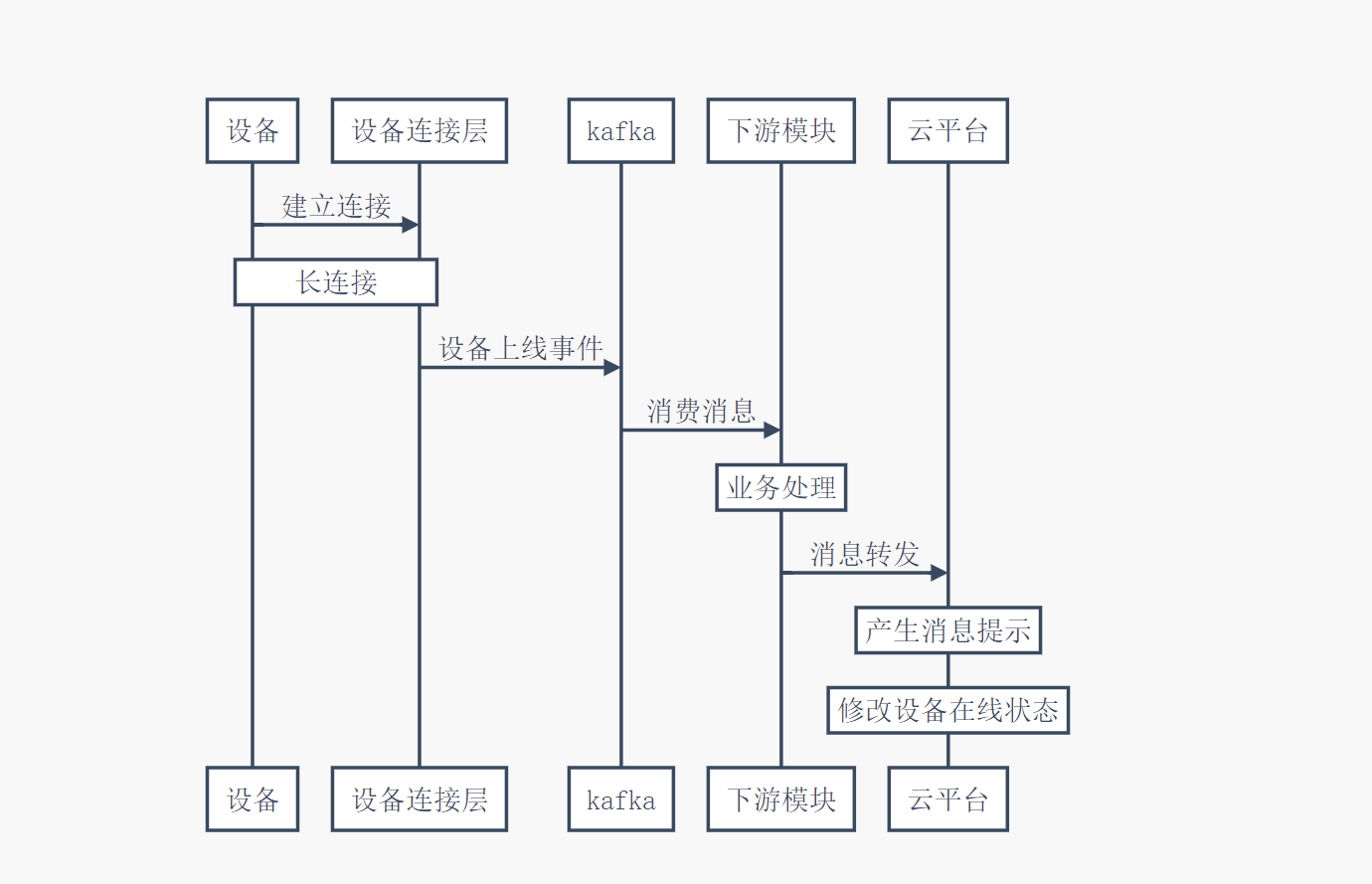
根据日志,初步定位问题原因是云平台未收到设备上线的消息,导致无法正确修改设备在线状态。
问题定位
测试环境使用约 50 个虚拟设备反复触发离线、上线逻辑,挂载数小时可复现。
继续添加日志定位问题:
- 在kafka处添加Debug打印,确认设备消息是否成功投递到kafka:消息丢失时间点,消息已成功投递到kafka
- 新增一个消费者来消费kafka的消息:消息丢失时,新增的消费者正常消费了消息
这两部分说明kafka消息队列没有问题,下游模块消费消息或是业务处理出现了问题。
下游模块处理流程:
- kafka 消费线程对包进行解析、封装
- 打印日志
- 限流判断,如果 TPS 大于 400 则进行限流处理
- 扔给业务线程池处理
- 打印日志
- 后续其他具体业务流程
2 打印正常、5 没有打印;在测试环境下远没有触发限流,3跳过;因此定位问题出在步骤4,业务线程池的处理出现了问题导致消息丢失。
线程池
基本概念
初始化时就建立好线程资源,避免反复创建新的线程造成的资源开销。
优点
- 降低资源消耗:减少新建和销毁线程所调用的资源
- 提高响应速度:任务到达时,不需要等待新建线程后执行任务
- 提高线程的可管理性:线程是有限的资源,如果创建太多可能会导致系统故障,使用线程池可以做到统一的分配,调用和监控
相关参数
threadPool:
corePoolSize: 20
maximumPoolSize : 2000
workQueue : 1000
keepAliveSeconds: 300
- 第1个参数:corePoolSize 表示常驻核心线程数
- 如果等于0,则任务执行完成后,没有任何请求进入时销毁线程池的线程
- 如果大于0,即使本地任务执行完毕,核心线程也不会被销毁
- 这个值的设置非常关键,设置过大会浪费资源,设置的过小会导致线程频繁地创建或销毁
- 第2个参数:maximumPoolSize 表示线程池能够容纳同时执行的最大线程数
- 必须大于或等于1
- 如果 maximumPoolSize 与 corePoolSize 相等,即是固定大小线程池。
- 第3个参数:workQueue 表示缓存队列
- 如果线程池里的线程数大于 corePoolSize,就会放到缓存队列
- 缓存队列满了会创建新线程到 maximumPoolsize
- 当请求的线程数大于 maximumPoolSize 时,会执行设定的策略,默认是拒绝创建策略
- 注意:当线程池里的线程数大于 corePoolSize 且小于 maximumPoolSize 时,这时候再有请求的线程就会放到缓存队列,注意只是放到缓存队列但是不创建新的线程,直到请求的线程存满缓存队列时,才会开始创建新的线程,直到 maxmunPoolSize 就会拒绝创建或者执行提前设定的策略
- 第4个参数:keepAliveSeconds 表示线程池中的线程空闲时间
- 当空闲时间达到 keepAliveSeconds 值时,线程被销毁,直到剩下 corePoolSize 个线程为止,避免浪费内存和句柄资源
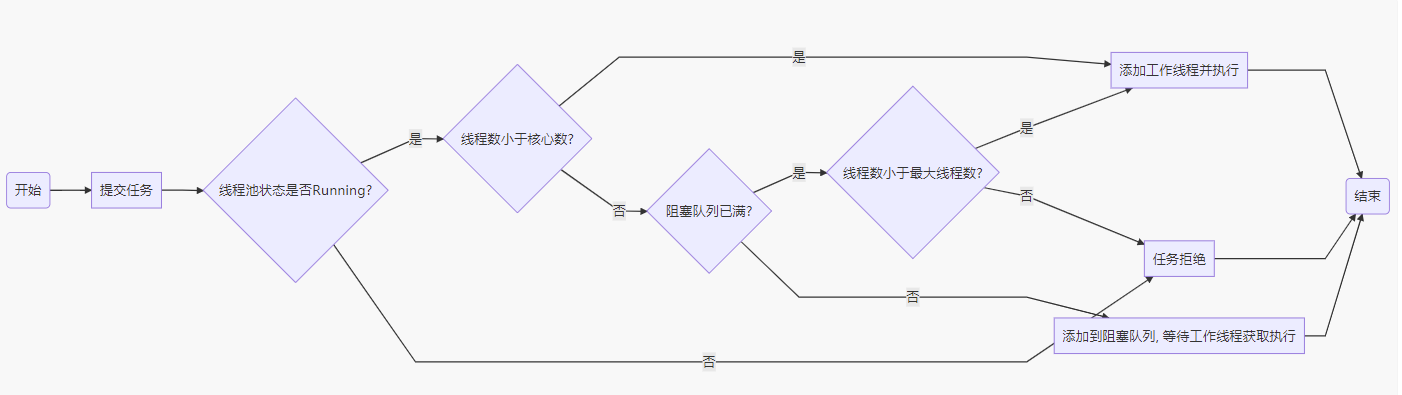
线程池工作流程大致如下:
graph LR
A(开始) --> B[提交任务]
B --> C{线程池状态是否Running?}
C --> |是|D{线程数小于核心数?}
D --> |是|E[添加工作线程并执行]
E --> F(结束)
C --> |否|G[任务拒绝]
G --> F
D --> |否|H{阻塞队列已满?}
H --> |是|I{线程数小于最大线程数?}
I --> |是|E
I --> |否|G
H --> |否|J[添加到阻塞队列, 等待工作线程获取执行]
J --> F
拒绝策略
当线程数大于 maximumPoolSize 时,会执行拒绝策略,常见的拒绝策略有四种:
-
CallerRunsPolicy(调用者运行策略)
- 当触发拒绝策略时,只要线程池没有关闭,就由提交任务的当前线程处理
- 使用场景:一般在不允许失败的、对性能要求不高、并发量较小的场景下使用,因为线程池一般情况下不会关闭,也就是提交的任务一定会被运行,但是由于是调用者线程自己执行的,当多次提交任务时,就会阻塞后续任务执行,性能和效率自然就慢了。
-
AbortPolicy(中止策略)
- 当触发拒绝策略时,直接抛出拒绝执行的异常,中止策略的意思也就是打断当前执行流程
- 使用场景:这个就没有特殊的场景了,但是有一点要正确处理抛出的异常。ThreadPoolExecutor 中默认的策略就是 AbortPolicy,ExecutorService 接口的系列 ThreadPoolExecutor 因为都没有显示的设置拒绝策略,所以默认的都是这个。但是请注意,ExecutorService 中的线程池实例队列都是无界的,也就是说把内存撑爆了都不会触发拒绝策略。当自己自定义线程池实例时,使用这个策略一定要处理好触发策略时抛的异常,因为他会打断当前的执行流程
-
DiscardPolicy(丢弃策略)
- 直接静悄悄的丢弃这个任务,不触发任何动作
- 使用场景:如果你提交的任务无关紧要,你就可以使用它。因为它就是个空实现,会悄无声息的吞噬你的的任务。所以这个策略基本上不用了
-
DiscardOldestPolicy(弃老策略)
- 如果线程池未关闭,就弹出队列头部的元素,然后尝试执行
- 这个策略还是会丢弃任务,丢弃时也是毫无声息,但是特点是丢弃的是老的未执行的任务,而且是待执行优先级较高的任务。基于这个特性,想到的场景就是,发布消息和修改消息,当消息发布出去后,还未执行,此时更新的消息又来了,这个时候未执行的消息的版本比现在提交的消息版本要低就可以被丢弃了。因为队列中还有可能存在消息版本更低的消息会排队执行,所以在真正处理消息的时候一定要做好消息的版本比较
实际配置的策略为 DiscardOldestPolicy,丢弃队列头部元素,即未执行的最旧的任务。
所以当阻塞队列已满、并且线程数也已经达到了最大线程数的时候,就会执行拒绝策略,导致消息丢失。
最终该问题定位的原因是线上消息压力过大,而配置的线程池参数过小、拒绝策略不合理,导致出现任务拒绝丢失消息。
合理设置线程池参数
首先确定以下几个相关参数:
- avgTasks,程序每秒需要处理的平均任务数量
- maxTasks,程序每秒需要处理的最大任务数量
- taskHandleTime,单线程处理一个任务所需要的时间
- responsetime,系统允许任务最大的响应时间
- peakTime,任务峰值持续时间
根据这几个参数,可以算出核心线程数、任务队列长度、最大线程数、线程空闲时间的推荐值
-
corePoolSize:常驻核心线程数
- 核心线程数需要能够满足平均负载
corePoolSize = avgTasks * taskHandleTime
-
maximumPoolSize:最大线程数
- 在峰值时,最大线程数需要能够处理所有的任务
maximumPoolSize = maxTasks * taskHandleTime
-
workQueue:缓存队列长度
- 缓存队列的长度是在核心线程满载和最大线程数之间的差距所能处理的任务数量,需要确保在响应时间内,队列中的任务可以被处理
workQueue = (maximumPoolSize - corePoolSize) * responseTime / taskHandleTime
-
keepAliveSeconds:最长线程空闲时间
- 当负载降低时,可减少线程数量,如果一个线程空闲时间达到 keepAliveTiime,该线程就销毁
- keepAliveTiime 是一个经验值,具体的值可能需要根据实际情况进行调整,也可根据任务峰值持续时间 peakTime 来设定